
State of Brand published a piece this week titled "Lovable hit $400M ARR. Then Anthropic made its move." Worth reading if you build software for a living. The short version: Lovable scaled from $1M to $400M ARR in about a year by routing every complex generation task through Claude. Then Anthropic launched Claude Design, which doesn't directly target Lovable yet, but it landed hard on Figma Make and showed how exposed any product built on top of someone else's model can be.
The piece doesn't claim Anthropic has shipped a Lovable competitor. It points out that Anthropic could, and that Figma Make just demonstrated what happens when the model owner decides to compete. That's the structural problem.
I want to talk about the architectural choice underneath that problem, because most people are reading the news as a competitive story and missing the engineering one.
The choice that determines everything
When you build an AI product, you make one decision early that shapes everything else. Either the LLM is the engine, or it sits at the edges.
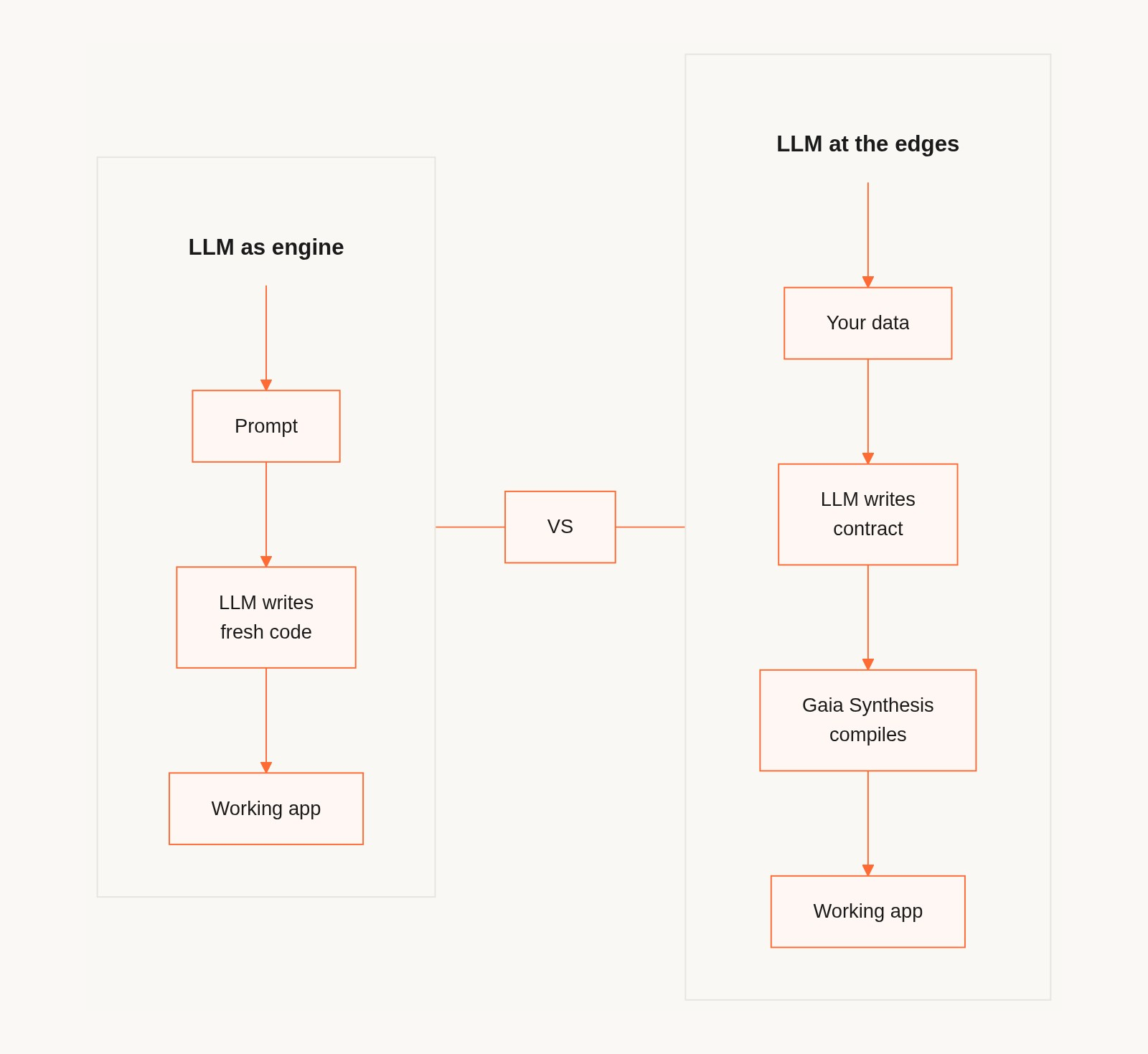
If the LLM is the engine, every output your users see is a fresh generation. Every feature is a prompt, every iteration is another round trip to a model you don't own. Your latency tracks the model's latency, your error rate tracks the model's error rate, your margins move when its pricing moves, and your roadmap is bounded by what the model can be coaxed into doing this quarter.
That's what Lovable built. The product looks great and the team has shipped fast. But Lovable doesn't control the generation engine. Anthropic does. Figma Make was in the same position when Claude Design dropped, and the State of Brand piece walks through how quickly that position turned uncomfortable. Lovable hasn't been targeted directly, but the surface area is the same.
The other path
The other path is to use the LLM where it earns its keep, and use a deterministic system to do the building.
That's how Gainable is built. Let me walk through what that means in practice.
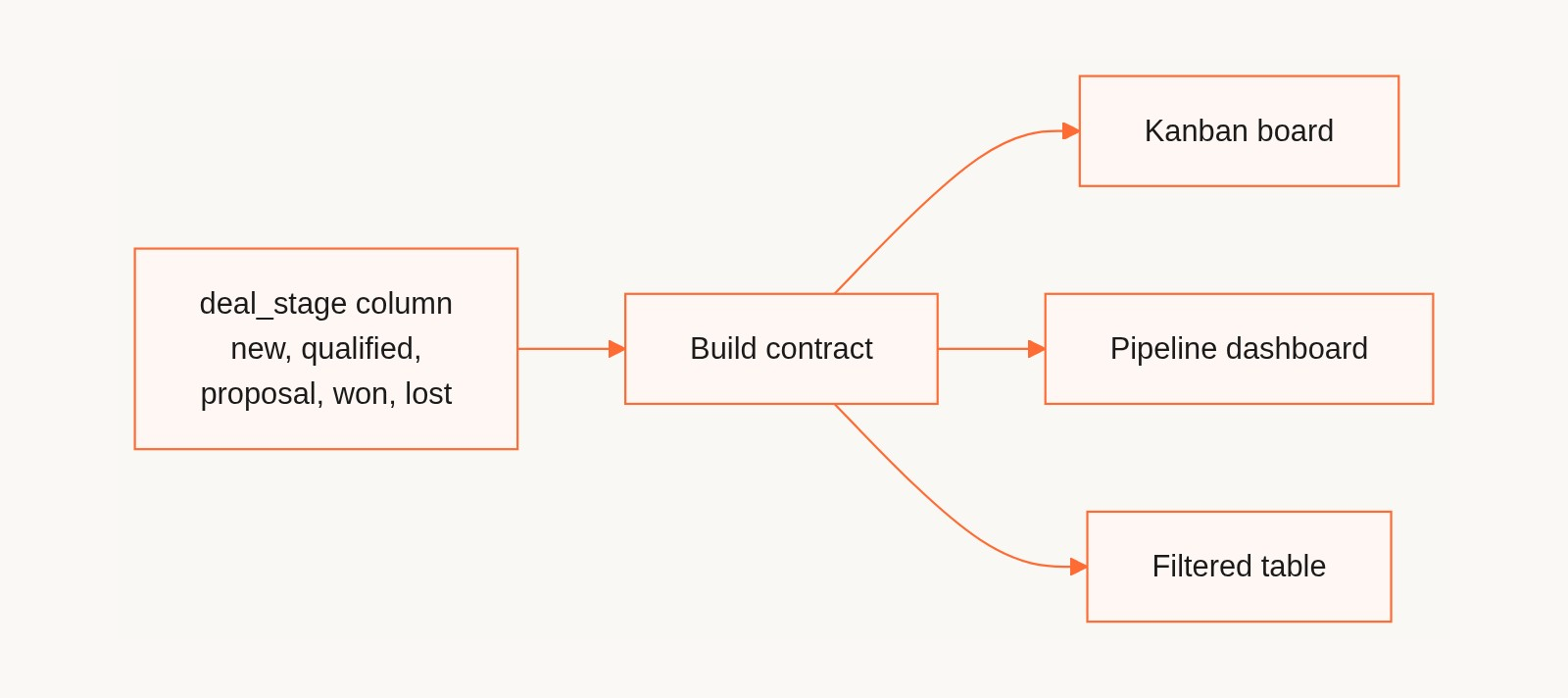
When you start an app in Gainable, the primary entry point isn't a text prompt. You upload a spreadsheet, a CSV, an Excel file, or you connect a data source like HubSpot, Stripe, Google Sheets, Airtable, or Supabase. The Gaia Data Model Agent reads the schema, the field types, the enum values, and the sample rows, infers the domain, and proposes an app spec.
Notice what just happened. The "prompt" is a real artifact of your business, structured and specific in a way no natural language description can match. A column called deal_stage with values new, qualified, proposal, won, lost carries more specification than a paragraph someone types into a chat box. We didn't invent a new prompt syntax. We made the data the prompt.
That's the first half of the architecture.
The second half is the part most people miss when they hear "AI app builder." The LLM does not write the application code. We have a proprietary compiler called Gaia Synthesis that takes a structured build contract and produces a complete, full-stack app in under a second. Node.js, Express, MongoDB, Alpine.js, DaisyUI, Tailwind, Weavy for collaboration, Chart.js for visualization, WebSockets for real-time, role-based auth, and an auto-generated REST API. All of it compiled from the contract, deterministically, the same way every time.
The LLM's job is to produce the contract. Gaia Synthesis's job is to produce the app. Two separate steps. One probabilistic, one deterministic.
That distinction is the whole moat. When Lovable or Bolt ship an app, an LLM is writing thousands of lines of fresh code on every build. Every line is a potential hallucination, a wrong API call, a layout that doesn't quite work. When Gainable ships an app, Gaia Synthesis is composing tested components against a contract it knows how to compile. There's nothing to hallucinate because the model isn't writing the code in the first place.
Then a second model runs validation. Haiku handles the contract-side generation under strict guardrails. Opus reviews every layer (forms, data flow, layout, logic) before delivery. Two different models doing two different jobs, against patterns that don't change between runs. That's how we keep error rates under 1% and how a Gainable app can be up to 90% smaller than the equivalent Lovable output.
The under-a-second build time isn't a marketing number. It's what falls out of compiling a contract instead of generating freeform code.
Why this matters for the bind these companies are in
If your product depends on the model being smart enough to write a fresh app every time, your fortunes track the model's. They also track whoever controls the model. When that company decides to build the same product you do, or even something adjacent, you have nowhere to retreat. Figma Make found that out in real time. Lovable hasn't, yet, but the architecture leaves the door open.
Gainable's architecture doesn't put us in that position. Gaia Synthesis is the engine. The compiler, the contract, the component library, the stack, and the patterns are all ours. The LLM is the part that produces the contract from your data, governed by everything around it. If pricing or availability shifts, or a better model becomes available, we have room to move because the model isn't doing the load-bearing work. The compiler is.
That's only possible because we treat the LLM as a tool we use, not a foundation we stand on.
The lead story is data, not prompts
I keep coming back to this because it matters. The reason you can put the LLM at the edges is that the data carries the spec.
When you upload a CRM export, Gainable knows what an opportunity is. It knows what a stage is. It knows what a close date implies for the layout. You don't need a 400-word prompt to get a pipeline view, because the structure of your data already says so. Gainable asks two or three clarifying questions to confirm. That's it. The app comes out the other side.
This is a different starting point than vibe coding. Vibe coding starts with vibes. We start with the artifact you already have and care about. The prompt is your spreadsheet.
Prompting is still useful. It's how you iterate. It's how you ask for a new view, a different filter, an extra dashboard. Prompts are the refinement layer, not the foundation. That ordering is the whole game.
What to take from the State of Brand piece
If you build on top of an LLM as the engine, three things happen over time. The model provider learns from your traffic. The model provider sees your roadmap in your API calls. The model provider eventually decides whether they want to be your platform or your competitor, or both at once. That decision is theirs, not yours. Figma Make is the most recent worked example. It probably won't be the last.
You can choose architecture that doesn't put you in that position. You build the things only you can build. You compose or buy the things others have already perfected. You use the LLM where it does what nothing else can, and you don't ask it to be the load-bearing wall.
Gainable sits in the internal tools category alongside Retool, Appsmith, and PowerApps, not in the vibe coding category Lovable plays in. Lovable is a fine tool for building consumer-facing web apps and front-end prototypes. That's a different problem from building production internal tools on live business data. But the architectural lesson cuts across categories. If you're building anything on top of an LLM, the question isn't which model to use. The question is what you're asking the model to be responsible for.
If the answer is "everything, including writing the code," you're a wrapper. If the answer is "the parts that benefit from inference, with a compiler doing the build," you have a product.
That's the line we drew. The State of Brand piece is a good reminder of why it matters.
If you want to see the data-first path in action, connect a spreadsheet to Gainable and watch the spec come out the other side. No prompt required.